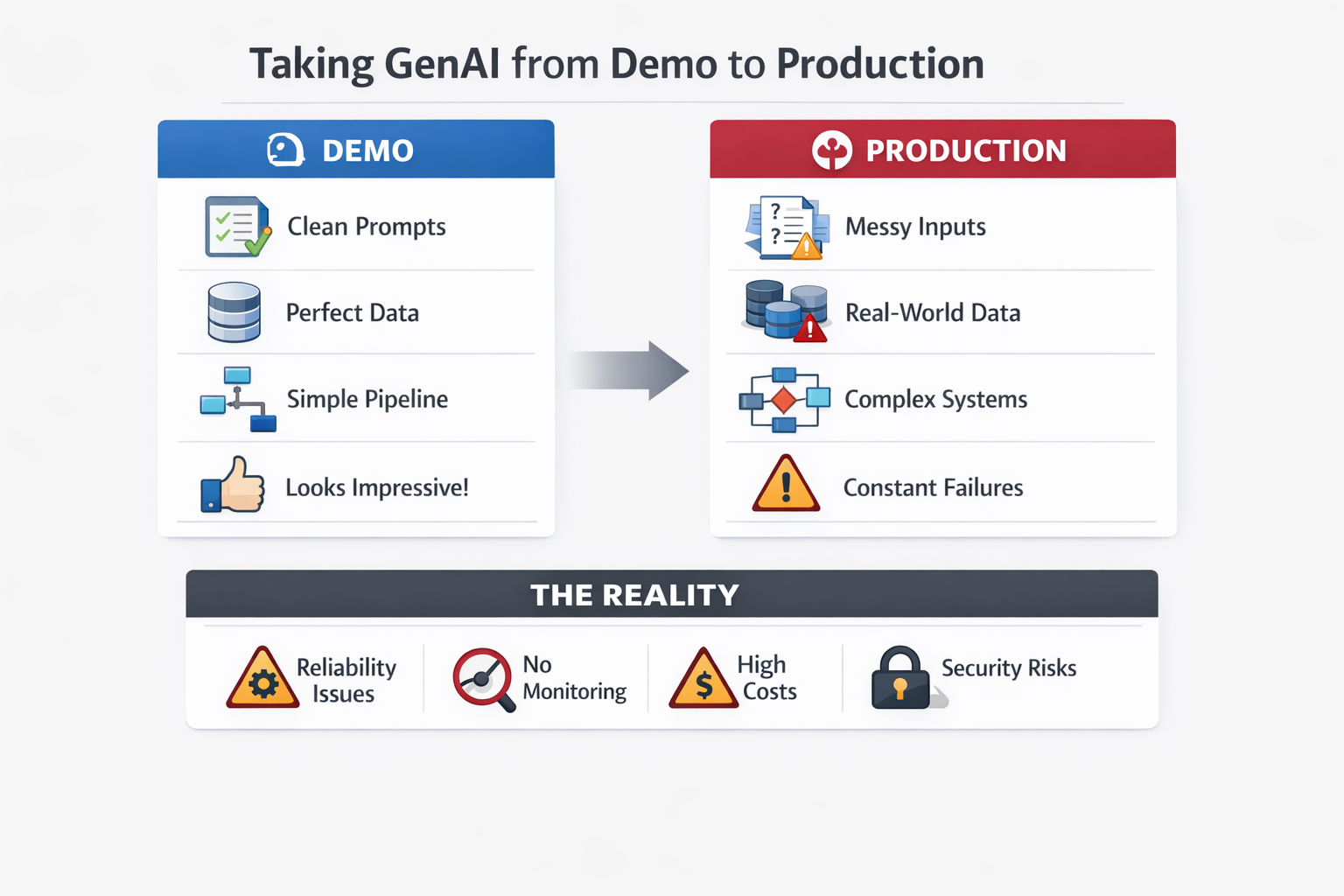
Most GenAI demos look magical.
A few prompts. Clean data. Impressive outputs.
It feels like the problem is solved.
Until you take the same system to production.
That is when things start breaking, not because the model is bad, but because the system around it was never designed for reality.
I have been building across RAG systems, document extractors, and AI agents, and one thing has been consistent:
What works in a demo is exactly what fails in production.
This post is a breakdown of what actually breaks, and why.
1. Clean Prompts Do Not Survive Messy Reality
In a demo environment:
- Inputs are curated
- Prompts are carefully crafted
- Edge cases are ignored
In production:
- Users type incomplete queries
- Documents are noisy or inconsistent
- Context is missing or ambiguous
That perfect prompt you tuned for hours was optimized for ideal conditions, not real-world variability.
2. Determinism Is an Illusion
LLMs do not behave like traditional software.
You do not get:
Same input -> same output
You get:
Same input -> slightly different outputs (sometimes significantly different)
In isolation, this might be acceptable.
But in production systems, especially multi-step pipelines or agent flows, small inconsistencies compound:
- One step introduces ambiguity
- Next step amplifies it
- Final output diverges completely
What looked stable in a demo becomes unreliable at scale.
3. The Real Shift: Prompt to System
Most demos are deceptively simple:
Prompt + LLM = Output
Production systems are not.
They require:
- Orchestration layers
- Retry mechanisms
- Fallback strategies
- Guardrails and validations
- State and context management
The core shift is this:
You are no longer building prompts. You are building systems.
Teams that miss this shift struggle the most.
4. RAG Systems Fail at Retrieval, Not Generation
Retrieval-Augmented Generation (RAG) looks straightforward in demos:
- Embed documents
- Retrieve relevant chunks
- Pass to LLM
In reality, retrieval is the hardest part.
Real example
We built a RAG-based document Q and A system.
In controlled testing, accuracy looked strong.
But in production, it started confidently returning incorrect answers.
The issue was not the model. It was retrieval.
The system would fetch a chunk that was semantically similar but contextually incorrect.
The LLM then generated a very convincing answer based on the wrong context.
From a user's perspective, this is dangerous:
- The answer sounds correct
- There is no obvious failure signal
The system fails silently with confidence.
5. Document Extraction Breaks on Edge Cases
Document extraction pipelines often look robust in demos.
You test against:
- Well-structured PDFs
- Consistent layouts
- Clean text
Then production happens.
Real example
We built a document extraction system that performed well on structured formats.
Once deployed, we encountered:
- Scanned PDFs
- Slight template variations
- Missing or shifted fields
The impact:
- Fields mapped incorrectly
- Values shifted between columns
- Confidence scores dropped inconsistently
The system did not crash. It degraded.
And subtle degradation is harder to detect than outright failure.
6. Lack of Observability Becomes a Major Bottleneck
In demos, evaluation is visual:
This looks correct.
In production, that is not enough.
You need to answer:
- Why did this fail?
- Where in the pipeline did it fail?
- Is this happening for all users or specific cases?
Without evaluation metrics, tracing, and logging across steps, you are operating without visibility.
And without visibility, you cannot improve the system.
7. Cost and Latency Are Hidden in Demos
Demos hide scale.
In production:
- Token usage grows rapidly
- Context windows expand
- Retry mechanisms multiply costs
- Embeddings add overhead
A system that costs a few dollars in testing can scale to thousands per month.
At the same time:
- Latency increases
- User experience degrades
You are suddenly optimizing not just for correctness, but for cost efficiency and response time.
8. Security and Compliance Become Real Constraints
This rarely shows up in demos.
In production, it becomes unavoidable:
- Personally identifiable information (PII)
- Data handling policies
- Audit requirements
- Model usage restrictions
Many GenAI systems do not fail technically.
They fail organizationally, because they cannot meet compliance requirements.
The Real Takeaway
The biggest misconception about GenAI is this:
It is not a model problem. It is a system problem.
The model is just one component.
The real challenges lie in:
- Data quality
- Retrieval accuracy
- System design
- Observability
- Cost control
- Reliability
What Actually Works
The teams that succeed with GenAI in production do one thing differently:
They stop treating it like a demo.
They treat it like:
- A distributed system
- A product
- An evolving system that needs monitoring and iteration
Final Thought
If your GenAI system works perfectly in a demo environment, that is a good start.
But it is not validation.
The real test begins when:
- Inputs are messy
- Users are unpredictable
- Scale increases
- Constraints appear
That is when you find out what actually holds, and what breaks.
If you have taken a GenAI system to production, you have likely seen some of these firsthand.
What broke first for you?
